


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
伊奈 拓也; 井戸村 泰宏; 今村 俊幸*; 小野寺 直幸
Proceedings of International Conference on High Performance Computing in Asia-Pacific Region (HPC Asia 2023) (Internet), p.29 - 34, 2023/02
ヤコビ前処理による混合精度クリロフソルバは、ヤコビ前処理をFP16やBF16のような低精度で計算した場合しばしば著しい収束性の悪化を示すことがある。この収束性の悪化はデータ変換時の丸め誤差により対角優位性が失われることに起因することがわかった。この問題を解決するために、元の行列データの対角優位性を保つように設計された新しいデータ変換方法を提案する。NVIDIA V100 GPU上でポアソン方程式を共役勾配法、双共役勾配安定化法、一般化最小残差法にFP16/BF16ヤコビ前処理を組み合わせた混合精度クリロフソルバによって計算することによって提案手法を検証する。データ変換はCUDAの組み込み関数を利用して最近接丸め、正の無限大丸め、負の無限大丸め、ゼロ方向丸めを切り替えて実装し、これが主反復の前に一度だけ呼び出される。したがって、提案するデータ変換にかかるコストは無視できる程度に小さい。連立一次方程式をスケーリングして行列の係数を連続的に変化させた場合に、最近接丸めによる従来のデータ変換では、対角係数と非対角係数の丸め誤差に依存して収束性が周期的に変化する。ここで、収束性悪化の周期と大きさは仮数部のビット長に依存する。一方、提案するデータ変換方式では収束性悪化を完全に回避できることが示され、ヤコビ前処理において余分なコストを伴わないロバストな混合精度計算が可能となった。
井戸村 泰宏; 伊奈 拓也*; Ali, Y.*; 今村 俊幸*
第34回数値流体力学シンポジウム講演論文集(インターネット), 6 Pages, 2020/12
ジャイロ運動論的トロイダル5次元full-fオイラーコードGT5Dにおける半陰解法差分計算用に新しいFP16(半精度)前処理付き省通信クリロフソルバを開発した。このソルバでは、大域的集団通信のボトルネックを省通信クリロフ部分空間法によって解決し、さらに収束特性を向上するFP16前処理によって袖通信を削減した。FP16前処理は演算子の物理特性に基づいて設計し、A64FXで新たにサポートされたFP16SIMD処理を用いた実装した。このソルバをGPUにも移植し、約1,000億格子のITER規模計算の性能を富岳(A64FX)とSummit(V100)で測定した。従来の非省通信型ソルバに比べて、新しいソルバはGT5Dを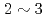 倍加速し、富岳とSummitの両方で5,760CPU/GPUまで良好な強スケーリングが得られた。
倍加速し、富岳とSummitの両方で5,760CPU/GPUまで良好な強スケーリングが得られた。
井戸村 泰宏; 伊奈 拓也*; Ali, Y.*; 今村 俊幸*
Proceedings of Joint International Conference on Supercomputing in Nuclear Applications + Monte Carlo 2020 (SNA + MC 2020), p.225 - 230, 2020/10
ジャイロ運動論的トロイダル5次元オイラーコードGT5Dにおける半陰解法差分ソルバ向けに新しいFP16(半精度)前処理付き省通信型クリロフソルバを開発した。このソルバでは、大域的集団通信のボトルネックを省通信型クリロフ部分空間法を用いて解決し、FP16前処理を用いて収束特性を改善することで袖通信の回数を削減した。FP16前処理は演算子の物理特性に基づいて設計され、A64FXにおいて新たにサポートされたFP16SIMD演算を用いて実装された。本ソルバは富岳(A64FX)とSummit(V100)に移植され、JAEA-ICEX(Haswell)に比べてそれぞれ 63倍, 29倍のソケットあたり性能の向上を達成した。
63倍, 29倍のソケットあたり性能の向上を達成した。
井戸村 泰宏; 伊奈 拓也*; 真弓 明恵; 山田 進; 今村 俊幸*
Lecture Notes in Computer Science 10776, p.257 - 273, 2018/00
被引用回数:2 パーセンタイル:50.01(Computer Science, Artificial Intelligence)前処理付チェビシェフ基底省通信共役勾配(P-CBCG)法を多相熱流体CFDコードJUPITERにおける圧力ポアソン方程式に適用し、8,208台のKNLプロセッサを搭載したOakforest-PACS上で計算性能と収束特性を前処理付共役勾配(P-CG)法や前処理付省通信共役勾配(P-CACG)法と比較した。P-CBCG法は収束特性のロバースト性を維持しつつ集団通信回数を削減する。このロバースト性向上により、P-CACG法と比べて一桁以上大きい省通信ステップ数を実現する。2,000プロセッサを用いた場合、P-CBCG法はP-CG法, P-CACG法と比べてそれぞれ1.38倍, 1.17倍高速であることを示した。
真弓 明恵; 井戸村 泰宏; 山田 進; 伊奈 拓也; 山下 晋
no journal, ,
多相多成分熱流動解析コードJUPITERのPoissonソルバに省通信CG法を実装し、実問題における収束特性と処理性能を調査した。省通信化に伴う数値誤差の蓄積による収束特性悪化の問題を分析し、アルゴリズムを部分的に4倍精度化して収束特性を向上する手法を考案した。
井戸村 泰宏
no journal, ,
省通信一般化最小残差(CA-GMRES)法をジャイロ運動論的トロイダル5次元オイラーコードに適用し、Oakforest-PACS(KNL)上で一般化共役残差(GCR)法に基づくオリジナルコードに対する性能比較を実施した。CA-GMRES法はGCR法に比べてメモリアクセスと集団通信が少なく、メモリとネットワークの帯域幅が制限された将来のエクサスケールアーキテクチャに適している。1280ノードを用いた場合、元のGCR版に比べてCA-GMRES版は1.32倍高速であり、データ縮約通信のコストが全体コストの約13%から約1%に削減されることが示された。
井戸村 泰宏
no journal, ,
ポスト京重点課題で開発を進めている核融合プラズマシミュレーションコードのエクサスケール計算技術を概説する。ITERの核燃焼プラズマは複数種のイオンから構成され、その時空間スケールは既存装置に比べて一桁以上大きくなる。このため、ITERにおける核燃焼プラズマシミュレーションはエクサスケール計算を必要とする。このような背景から、本研究では最先端メニーコアプロセッサ上での高効率計算を可能とし、ノード間通信を削減する新たな計算技術を5次元核融合プラズマ乱流コードGT5Dにおいて開発し、8,208台のXeonPhi7250(KNL)プロセッサを搭載したOakforest-PACSにおいてその性能を実証した。
井戸村 泰宏
no journal, ,
最先端メニーコア環境における大規模原子力CFDシミュレーションにおいて開発を進めている計算技術を概説する。原子力機構では、過酷事故時の原子炉の溶融移行挙動や放射性物質の環境動態等の重要課題の解析に向けて大規模CFDシミュレーションが必要とされている。最先端メニーコア環境はこのような大規模計算需要に対する有望な解決策であるが、演算加速によってノード間通信やデータI/Oのボトルネックが顕在化する。この問題を解決するために、3次元多相多成分熱流動解析コードJUPITERにおいて新たな省通信行列ソルバやIn-Situ可視化システムを開発し、8,208台のXeonPhi7250(KNL)プロセッサを搭載したOakforest-PACSにおいてその性能を実証した。
井戸村 泰宏; 伊奈 拓也*; 真弓 明恵; 山田 進; 松本 和也*; 朝比 祐一*; 今村 俊幸*
no journal, ,
本研究ではオリジナルの省通信一般化最小残差(CA-GMRES)法と同じ省通信特性を維持しつつ計算量とメモリーアクセスを30%削減する修正CA-GMRES法を提案する。より高い演算密度、かつ、より少ない通信量と計算量という演算特性はメモリ帯域幅と通信帯域幅が制限される将来のエクサスケール計算機に対して有望な特徴である。修正CA-GMRES法をジャイロ運動論的トロイダル5次元オイラーコードGT5Dの陰解法ソルバにおける大規模非対称行列に適用し、Oakforest-PACS(KNL)において性能評価を行った。数値実験結果から、一般化共役残差法と比べて、演算カーネルは1.5倍高速化され、1,280ノード利用時のデータ縮約通信コストは全体コストの12.5%から1%に削減されることが示された。
真弓 明恵; 井戸村 泰宏; 伊奈 拓也*; 山田 進; 今村 俊幸*
no journal, ,
多相CFDコードJUPITERにおける圧力ポアソン方程式のような悪条件問題に省通信共役勾配(CA-CG)法を適用する上で収束特性の向上が必要となっている。CA-CG法では省通信ステップ数を増やすことでより多くの通信を削減できるが、数値誤差に対するロバースト性が悪化する。この問題を解決するために、チェビシェフ基底CG(CBCG)法をJUPITERに適用する。
今村 俊幸*; 井戸村 泰宏; 伊奈 拓也*; 山下 晋; 小野寺 直幸; Ali, Y.*; 山田 進
no journal, ,
ポスト京におけるエクサスケール計算に向けて、省通信アルゴリズムに基づく新たな行列ソルバが開発されている。本講演では、3次元多相熱流動解析CFDコードJUPITERで用いられている2つの手法を紹介する。一つは省通信クリロフ部分空間法である。この手法では複数の基底ベクトルの生成、直交化を一度に処理することで大域的集団通信の回数を削減する。もう一つ手法であるマルチグリッド前処理付クリロフ部分空間法は収束特性を飛躍的に向上し、反復、すなわち、大域的集団通信の回数を削減する。最新のメニーコア環境におけるこれらの手法の比較を議論する。
伊奈 拓也; 井戸村 泰宏; 今村 俊幸*; 山下 晋; 小野寺 直幸
no journal, ,
多相多成分熱流動解析コードJUPITERの前処理付き共役勾配法(PCG法)向けに混合精度前処理を開発した。この前処理はFP16データとFP32演算を組み合わせたハイブリッドな混合精度演算を採用している。FP16でメモリ上に保存したデータをキャッシュ上でFP32に変換して中間結果をFP32で演算して最終結果をFP16に変換してメモリに戻すことで丸め誤差を低減する。開発した前処理を3,200 2,00014,160の3次元構造格子を用いた大規模問題で性能測定を実施した。その結果、悪条件行列にFP16データ形式を用いてもPCG法の収束性を維持しつつ、メモリアクセスを削減することでスーパーコンピュータ富岳の2000ノードでFP64前処理実装から1.79倍の高速化を達成した。
2,00014,160の3次元構造格子を用いた大規模問題で性能測定を実施した。その結果、悪条件行列にFP16データ形式を用いてもPCG法の収束性を維持しつつ、メモリアクセスを削減することでスーパーコンピュータ富岳の2000ノードでFP64前処理実装から1.79倍の高速化を達成した。
井戸村 泰宏
no journal, ,
ジャイロ運動論的トロイダル5次元オイラーコードGT5Dでは、トーラスプラズマ全体を5次元格子で解像するため、ITERの炉心プラズマ解析には「富岳」を活用したエクサスケール計算が必須となる。これを実現するために、GT5Dにおいて8割以上のコストを占める半陰解法差分計算用に新しいFP16前処理付き省通信クリロフソルバを開発した。このソルバでは、大域的集団通信のボトルネックを省通信クリロフ部分空間法によって解決し、さらにFP16前処理により収束特性を向上することによって袖通信を削減した。FP16前処理は演算子の物理特性に基づいて設計し、FP16SIMD処理を用いて実装した。これにより、約1,000億格子のITER規模計算の性能を従来ソルバに比べて約3.5倍加速し、5,760ノードまで良好な強スケーリングを達成した。
井戸村 泰宏
no journal, ,
Oakforest-PACS(OfP)はKNL, MCDRAM等の新技術によって従来のマルチコアプロセッサ環境に比べて飛躍的に高い演算性能とメモリバンド幅を実現し、現在主流となっている省電力メニーコアプロセッサに基づくエクサスケール計算機のプロトタイプとして重要な役割を果たした。本研究では、OfP上で富岳向けの大規模原子力流体解析の開発に取り組んできたが、特に、演算加速によって顕在化した通信処理のボトルネックが重要な課題となった。この課題解決に向けて、主要な計算コストを占める大規模疎行列の反復解法において、省通信クリロフ部分空間法や省通信マルチグリッド法といった省通信型行列解法を開発し、OfP全系規模の高性能CFD解析を実現した。講演では、5次元プラズマ流体解析コードGT5Dや3次元多相多成分熱流動解析コードJUPITERにおける省通信型行列解法の事例を紹介する。
伊奈 拓也; 井戸村 泰宏; 今村 俊幸*; 山下 晋; 小野寺 直幸
no journal, ,
「富岳」や「Summit」をはじめとする最先端スーパーコンピュータでは倍精度演算性能よりも低精度演算性能の方が数倍高く、FP16やBfloat16を活用した混合精度処理が有効である。しかし、多相CFDシミュレーションの悪条件行列に対する反復解法に低精度演算をそのまま適用すると収束性の悪化を引き起こす問題がある。これまで、多相熱流動解析コードJUPITERを対象としてクリロフ部分空間法の混合精度前処理を構築し、A64FXでは行列のスケーリングとFP16データ/FP32演算混合精度前処理により収束性の維持と高速化を実現した。本研究では、NVIDIA GPUでサポートされているBFloat16を用いて混合精度前処理の検証を行った。Bfloat16はFP32と同等なダイナミックレンジを持つためFP16では必須であるオーバーフローを防ぐためのスケーリングは不要である。その結果、Bfloat16を用いることでFP16を使用した場合と比較して前処理で7%の高速化を確認した。しかし、仮数部のビット数がFP16よりも少ないBfloat16では収束性が悪化するケースも見られた。
加藤 凛乃*; 肥田 剛典*; 堤 英明*; 高田 毅士
no journal, ,
原子力施設のより現実的な地震応答解析モデルの構築を目的に、実地震時における強震観測記録を最大限に活用してわれわれの開発したシステム同定手法を利用して、モデル構築を行い、その妥当性検証も行った。
伊奈 拓也; 井戸村 泰宏; 今村 俊幸*
no journal, ,
最先端のスーパーコンピュータは、Nvidia、AMD、Intelなど、さまざまなアーキテクチャのCPU/GPUを搭載しており、各メーカーはそれぞれのアーキテクチャに対応した独自のプログラミング環境を提供している。そのため、スーパーコンピュータごとに異なるプログラミング環境を用いてコードを開発する必要がある。また、機械学習の高い計算ニーズにより、低精度浮動小数点演算性能は倍精度浮動小数点演算性能の数倍となっており、低精度浮動小数点演算性能の重要性が高まっている。しかし、各アーキテクチャは浮動小数点のハードウェアサポートが異なる。そのため、未対応の浮動小数点を使用した場合、計算ができなかったり、ソフトウェアエミュレーションにより性能が低下したりするという問題がある。インテルが推奨するプログラミングモデルであるDPC++は、C++をベースにKhronosグループが標準化した移植可能なプログラミング言語であるSYCLを実装したものであり、1つのソースコードで複数のCPU/GPU上で動作させることができる。また、SYCLには複数の実装が存在するため、アーキテクチャや使用するアルゴリズムに適した実装を選択することで、性能向上が期待できる。本研究では、3次元ポアソン方程式に対して、SYCLを用いた複数精度共役勾配ソルバーの性能を、圧縮行格納形式と対角格納形式の疎行列格納形式で評価した。
